https://www.codeproject.com/Articles/522094/Outlook-add-in-using-VCplusplus-ATL-COM
'팁 > URL' 카테고리의 다른 글
| 펌] 각 언어별 딥러닝~ 라이브러리. (0) | 2017.01.17 |
|---|---|
| CUDA (0) | 2016.12.12 |
| GIT 튜토리얼. (0) | 2016.12.08 |
| NVIDIA, CUDA (0) | 2016.11.23 |
https://www.codeproject.com/Articles/522094/Outlook-add-in-using-VCplusplus-ATL-COM
| 펌] 각 언어별 딥러닝~ 라이브러리. (0) | 2017.01.17 |
|---|---|
| CUDA (0) | 2016.12.12 |
| GIT 튜토리얼. (0) | 2016.12.08 |
| NVIDIA, CUDA (0) | 2016.11.23 |
MFC로 프로그래밍을 하다 보면, 각 클래스에 어떻게 접근해서 포인터를 얻어와야 하는지 매우 어려울 때가 많다...
특히 초중급자 시절엔 말이다.. 사용한 지 오래 되어도 여전히 헷갈리기는 매 한가지다.
자 그럼.. 하나씩.. 이해해 보자.
우선 MFC로 프로그램을 만들면, 다음과 같이 클래스가 생성된다. 프로젝트 명을 Test라고 가정해 보자.
CTestApp - CWinApp 클래스를 상속, 프로그램 초기화 클래스 (InitInstance)
CMainFrame - CFrameWnd 클래스를 상속, 전체 윈도우 관련 클래스(툴바, 메뉴, 상태바 등등)
CTestDoc - CDocument 클래스를 상속, 문서 관련 클래스(Open, Save, Serialize)
CTestView - CView 클래스를 상속, 사용자 화면 클래스(OnPaint, OnDraw)
CAboutDlg - CDialog 클래스를 상속, 도움말 대화 상자 클래스(DoModal)
-------------------------------------------------*^^*--------------------------------------------------
우선 가장 쉬운 것부터 설명하자면,
어느 곳에서나 CTestApp의 포인터를 얻고자 한다면, 다음과 같이 코딩한다.
AfxGetApp()는 전역 함수이므로 어느 곳에서나 호출할 수 있다.
CTestApp* pApp = AfxGetApp();
하지만 위와 같이 사용하면, 다음과 같은 에러가 발생한다.
error C2440: 'initializing' : cannot convert from 'class CWinApp *' to 'class CTestApp *'
에러를 보면, CWinApp*를 CTestApp*로 변환할 수 없다는 것인데, AfxGetApp()의 함수 원형이
CWinApp* AfxGetApp();
이기 때문이다. 그래서 이 문제를 해결하기 위해서는 아래와 같이 형변환(casting)을 해 주어야 한다.
CTestApp* pApp = (CTestApp*)AfxGetApp();
이제는 컴파일 에러 없이 잘 될 것이다. 그리고 다음과 같은 에러가 발생될 수도 있느데,
error C2065: 'CTestApp' : undeclared identifier
이는 CTestApp 클래스의 선언 부분이 포함(include)되지 않았기 때문이다. 이럴 때는
CTestApp 클래스의 선언을 다음처럼 포함시켜야 한다.
#include "Test.h"
pApp는 이미 생성되어 있는 CTestApp의 객체 포인터이기 때문에,
이젠 pApp 포인터를 통해 CTestApp 객체에 쉽게 접근할 수 있다. 만약에 CTestApp에
int i;
라는 멤버 변수가 있었다면,
pApp->i = 5;
와 같이 사용할 수 있다. 또한 멤버 함수 func()가 있다면,
pApp->func();
처럼 접근할 수 있다. 주의해야 할 것은 객체 접근이기 때문에 public 속성의 멤버들만 접근할 수 있고,
private와 protected는 접근할 수 없음에 유의해야 한다.
-------------------------------------------------*^^*--------------------------------------------------
두 번째는 CMainFrame의 포인터을 얻어 오는 방법이다. 다음과 같이 사용하려 할 때,
CMainFrame* pFrame = AfxGetMainWnd();
두 가지 에러와 만나게 된다.
첫 번째, CMainFrame에 대해서 컴파일러가 모르겠다는 에러이다.
error C2065: 'CMainFrame' : undeclared identifier
이 에러를 수정하기 위해서는 CMainFrame 클래스가 선언되어 있는 헤더 파일을
다음처럼 포함시키면 된다. 그리고 포함시키는 위치도 Test.h와 TestDoc.h 사이가 좋다.
그것은 클래스들간에 서로 관계가 있기 때문에 포함 순서는 매우 중요하다.
#include "stdafx.h"
#include "Test.h"
#include "MainFrm.h"
#include "TestDoc.h"
#include "TestView.h"
이 에러를 해결하고 나면, 다음과 같이 CTestApp에서 발생했던 에러가 발생한다.
error C2440: 'initializing' : cannot convert from 'class CWnd *' to 'class CMainFrame *'
에러를 보면, CWnd*를 CMainFrame*로 변환할 수 없다는 것인데, AfxGetMainWnd()의 함수 원형이
CWnd* AfxGetMainWnd();
이기 때문이다. 그래서 이 문제를 해결하기 위해서는 아래와 같이 형변환(casting)을 해 주어야 한다.
CMainFrame* pFrame = (CMainFrame*)AfxGetMainWnd();
이제는 컴파일 에러 없이 잘 될 것이다. CMainFrame은 CFrameWnd를 상속 받고, CFrameWnd는
CWnd를 상속 받기 때문에, pFrame 포인터를 통해서 CFrameWnd와 CWnd가 갖고 있는 모든 함수를
호출하여 사용할 수 있다. 만약 윈도우의 타이틀에 나오는 제목을 바꾸고 싶다면,
pFrame->SetWindowText( "야.. 바뀌어라" );
처럼 사용하면 된다.
-------------------------------------------------*^^*--------------------------------------------------
CMainFrame*는 또 다른 이유로 자주 사용하게 되는데, 그 이유는 도큐먼트(CTestDoc)와
뷰(CTestView) 클래스에 접근하기 위해서이다. CMainFrame 클래스는 뷰에 접근하는 GetActiveView(); 함수와
문서에 접근하는 GetActiveDocument() 함수를 제공한다.
우리가 어느 특정 클래스를 만들어서 사용하고, 이 클래스가 뷰에 접근해야 한다면 다음과 같은 문장을 사용해야 한다.
CMainFrame* pFrame = (CMainFrame*)AfxGetMainWnd();
CTestView* pView = (CTestView*)pFrame->GetActiveView();
만약 도큐먼트 클래스에 접근해야 한다면,
CMainFrame* pFrame = (CMainFrame*)AfxGetMainWnd();
CTestDoc* pDoc = (CTestDoc*)pFrame->GetActiveDocument();
물론 이 때는 각각의 클래스에 대한 헤더를 반드시 포함시켜야 함을 잊지 말아야 된다.
가끔 아래와 같은 순서로 헤더를 포함시키지 않는 경우가 있는데, 반드시 아래와 같이 포함해야 한다.
#include "MainFrm.h"
#include "TestDoc.h"
#include "TestView.h"
만약 대화 상자에서 도큐먼트 클래스에 접근하려면 어떻게 할 것인가? 방법은 위와 동일하다.
-------------------------------------------------*^^*--------------------------------------------------
다음은 뷰에서 도큐먼트에 접근하는 것과 도큐먼트에서 뷰에 접근하는 것에 대해 알아보자.
뷰와 도큐먼트는 서로를 직접 접근할 수 있는 함수가 제공된다. 뷰에서 도큐먼트를 직접 접근하려면,
CTestDoc* pDocument = (CTestDoc*)GetDocument();
를 호출하면 된다. 물론 View 클래스에는 GetDocument() 함수가 존재해야 한다. 일반적으로 이 함수는
MFC로 프로젝트 생성 시 기본적으로 있다. 하지만 만약 직접 만든 새로운 클래스라면 GetDocument() 함수를
직접 만들어줘야 한다. 직접 만들기가 귀찮다면, 다음과 같이 사용해도 된다.
CTestDoc* pDocument = (CTestDoc*)m_pDocument;
m_pDocument는 CTestView 클래스의 멤버이며, 다음과 같이 선언되어 있다.
CDocument* m_pDocument;
그리고, 도큐먼트에 뷰 클래스를 참조하려면 아래와 같이 해야 한다.
POSITION pos = GetFirstViewPosition();
CTestView* pView = (CTestView*)GetNextView( pos );
도큐먼트는 뷰 클래스를 내부적으로 링크드리스트를 사용해서 관리하고 있다. 그러므로 GetFirstViewPosition()
함수를 통해 POSITION을 얻어 온 다음, GetNextView() 함수를 통해 뷰의 포인터를 얻어오면 된다.
만약 창 분할에 의해 뷰가 여러 개 존재한다면, 다음과 같이 얻어 올 수 있다. 만약 컴파일 에러가 발생하면,
#include "TestView.h" 처럼 해서 헤더 파일을 포함하는 것도 잊지 말자.
POSITION pos = GetFirstViewPosition();
CTestView1* pView1 = (CTestView1*)GetNextView( pos );
CTestView2* pView2 = (CTestView2*)GetNextView( pos );
CTestView3* pView3 = (CTestView3*)GetNextView( pos );
CTestView4* pView4 = (CTestView4*)GetNextView( pos );
...
-------------------------------------------------*^^*--------------------------------------------------
그렇다면,,, CTestApp 클래스에서 뷰(CTestView) 클래스는 어떻게 얻어 올 수 있을까? 쉽게 응용할 수 있지만
머리가 꽉 막힐 수도 있다. 이 곳에서도 혹시 에러가 나면 헤더 파일을 자~알 추가해야 할 것이다.
CMainFrame* pFrame = (CMainFrame*)AfxGetMainWnd();
CTestView* pView = (CTestView*)pFrame->GetActiveView();
-------------------------------------------------*^^*--------------------------------------------------
마지막으로, 뷰(CTestView) 클래스에서 CMainFrame에 접근할 수 있는데 AfxGetMainWnd() 함수외에도
CMainFrame* pFrame = (CMainFrame*)GetParentFrame();
-------------------------------------------------*^^*--------------------------------------------------
MDI 환경에서 포인터를 가져와 보자.
CTestApp* pApp = (CTestApp*)AfxGetApp();
POSITION pos = pApp->GetFirstDocTemplatePosition();
CDocTemplate* pDocTemplate;
pDocTemplate = pApp->GetNextDocTemplate( pos ); // 첫 번째 등록한 템플릿
pDocTemplate->OpenDocumentFile( NULL ); // 첫 번째 문서 생성
POSITION posDoc = pDocTemplate->GetFirstDocPosition();
CTestDoc* pDoc = (CTestDoc*)pDocTemplate->GetNextDoc( posDoc ); // 첫 번째 문서 포인터
ASSERT( pDoc->IsKindof( RUNTIME_CLASS(CMongDoc) ) ); // 포인터 유효성 검사
//CXXXDoc* pDoc2 = (CXXXDoc*)pDocTemplate->GetNextDoc( posDoc ); // 두 번째 문서 포인터
POSITION posView = pDoc->GetFirstViewPosition();
CTestView* pView = (CTestView*)pDoc->GetNextView( posView ); // 첫 번째 뷰 포인터
ASSERT( pView->IsKindof( RUNTIME_CLASS(CTestView) ) ); // 포인터 유효성 검사
//CXXXView* pView2 = (CXXXView*)pDoc->GetNextView( posView ); // 두 번째 뷰 포인터
//ASSERT( pView2->IsKindof( RUNTIME_CLASS(CXXXView) ) ); // 포인터 유효성 검사
// 다음 템플릿이 존재할 경우만 가능합니다.
pDocTemplate = pApp->GetNextDocTemplate( pos ); // 두 번째 등록한 템플릿
if( pDocTemplate ) // 두 번째 템플릿이 존재하는지 검사
{
pDocTemplate->OpenDocumentFile( NULL ); // 두 번째 문서 생성
}
-------------------------------------------------*^^*--------------------------------------------------
분할 뷰에서는 위의 방법과 같이 포인터를 얻어 올 수 있다. 또는 다음과 같은 방법으로 얻어 올 수 있다.
만약 창이 두 개로 분할되어 있다면,
CMainFrame* pFrame = (CMainFrame*)AfxGetMainWnd();
CTestView* pView1 = (CTestView*)pFrame->m_wndSplitter.GetPane(0,0); // 첫 번째 뷰 포인터 얻기
CXXXView* pView2 = (CTestView*)pFrame->m_wndSplitter.GetPane(0,1); // 두 번째 뷰 포인터 얻기
뷰 포인터는 다음과 같이 좌표를 사용하여 구할 수 있다.
---------------------------------------------
| | |
| GetPane( 0, 0 ) | GetPane( 0, 1 ) |
| | |
---------------------------------------------
| | |
| GetPane( 1, 0 ) | GetPane( 1, 1 ) |
| | |
--------------------------------------------------------------------
| | | |
| GetPane( 2, 0 ) | GetPane( 2, 1 ) | GetPane( 2, 2 ) |
| | | |
--------------------------------------------------------------------
펌:http://egloos.zum.com/indra207/v/5175542
| 파일 관련 API 정리. (0) | 2016.11.22 |
|---|
출처: http://appmaid.tistory.com/11 [App Maid]
AI Korea Open 그룹에서도 라이브러리에 관한 투표가 있었고, 많은 분들이 관심있어할 만한 부분이라 생각해서 한 번 정리해 봤습니다!
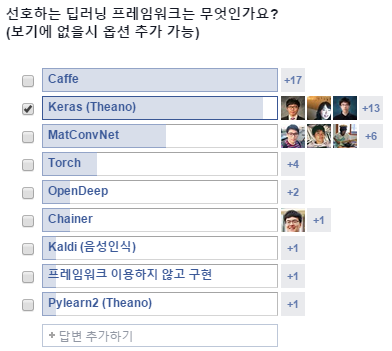 (AI Korea Open 그룹의 투표 결과)
(AI Korea Open 그룹의 투표 결과)
요즘 뜨는 언어답게, 대부분의 라이브러리들이 빠른 속도로 업데이트되며 새로운 기능이 계속 추가되고 있다.
자바스크립트로의 딥러닝 구현은 Stanford의 Andrej Karpathy가 혼자서 개발했음에도 불구하고 높은 완성도를 보이며 널리 사용되고 있는 아래 두 라이브러리가 가장 유명하다.
MIT에서 새로 개발한 언어로, 최근에 주목받기 시작하여 효율적인 딥 러닝 라이브러리도 여러 가지 구현되었다.
출처: http://www.teglor.com/b/deep-learning-libraries-language-cm569/ 블로그 포스트 자료에서 약간의 수정을 거쳤습니다.
작성자: 최명섭, 김주용
| OUTLOOK PLUG IN (0) | 2018.04.04 |
|---|---|
| CUDA (0) | 2016.12.12 |
| GIT 튜토리얼. (0) | 2016.12.08 |
| NVIDIA, CUDA (0) | 2016.11.23 |
커널함수는 비동기 함수이기 때문에, 동기화 처리시, cudaDeviceSynchronie() 함수를 호출하면 된다.
| 스트림. (0) | 2017.01.04 |
|---|---|
| 고정 메모리와 제로 메모리 그리고 포터블 메모리. (0) | 2017.01.03 |
| 메모리 타입. (0) | 2017.01.03 |
| CUDA 컴파일 옵션. (0) | 2017.01.03 |
| 쓰레드 ID 구하기. (0) | 2016.12.29 |
- 소개.
쿠다는 아래와 같이 처리를 하는데, 데이터를 복사하는 과정과 GPU 처리 과정이 순차적으로 처리가 되기 때문에, 1번 과정에서 GPU는 대기하게 되어, 동시성이 떨어진다.
이와 같이 대기 시간을 줄이기 위해, 데이터를 작은 단위로 나뉘고 데이터 전송이 완료된 것 부터 GPU에서 계산하는 동시에 계속해서 데이터를 전송하도록 개선 했는데, 이를 스트림이라고 한다.
1. 호스트에서 디바이스로 입력 데이터 복사.
2. 커널함수 데이터 처리.
3. 처리결과를 디바이스->호스트로 복사.
-특징
- 순차적으로 처리를 해야 하는 의존적인 데이터에 대해서도 스트림은 순차적으로 처리를 한다.
- cudaMallocHost() 를 이용해서 고정된 메모리[pinned Memory] 사용해야 한다.
- 커널함수<<<1,2,3,stream>>>() - 4번재 항목에 적용된다. 명시하지 않으면 기본값 stream 0 이 할당된다.
- 관련 API
1. cudaStreamCreate()
2. cudaMemcpyAsync();
3. cudaStreamDestroy()
- 샘플코드
__global__ void kernel( int*In, int*Out) { int tid = blockIdx.x * blockDim.x+ threadIdx.x; for(int i=0;i<5;i++) Out[tid] += In[tid]; } int main() { const int nStreams = 15; //스트림 분할 개수 const int nBlocks = 65535; //블록의 개수 const int nThreads = 512; //스레드의 개수 const int N = 512*65535; //데이터의 개수 const int Size = N*sizeof(int); //버퍼의 사이즈 int* host_In; int* host_Out; //호스트 메모리 할당 cudaMallocHost((void**)&host_In,Size); cudaMallocHost((void**)&host_Out,Size); //데이터 입력 for( int i = 0; i < N; i++) { host_In[i] = i; host_Out[i] = 0; } int* dev_In; int* dev_Out; //디바이스 메모리 할당 cudaMalloc((void**)&dev_In, Size); cudaMalloc((void**)&dev_Out, Size); cudaMemset(dev_In, 0, Size); cudaMemset(dev_Out, 0, Size); //스트림 객체 생성 cudaStream_t *streams = (cudaStream_t*) malloc(nStreams * sizeof(cudaStream_t)); for(int i = 0; i < nStreams; i++) cutilSafeCall( cudaStreamCreate(&(streams[i])) ); //병행 실행 시간 측정 cudaEvent_t StreamStart, StreamStop; float StreamTime; cudaEventCreate(&StreamStart); cudaEventCreate(&StreamStop); int offset = 0; cudaEventRecord(StreamStart, 0); //호스트 디바이스 입력 데이터 전송 for(int i = 0; i < nStreams; i++) { offset= i*N/nStreams; cudaMemcpyAsync(dev_In + offset, host_In + offset, Size, cudaMemcpyHostToDevice, streams[i]); } //덧셈 계산 for(int i = 0; i < nStreams; i++) { offset= i*N/nStreams; kernel<<<nBlocks/nStreams,nThreads, 0, streams[i]>>>(dev_In+offset, dev_Out+offset); } //디바이스 호스트 출력 데이터 전송 for(int i = 0; i < nStreams; i++) { offset= i*N/nStreams; cudaMemcpyAsync(host_Out + offset, dev_Out + offset, Size, cudaMemcpyDeviceToHost, streams[i]); } cudaEventRecord(StreamStop, 0); cudaEventSynchronize(StreamStop); cudaEventElapsedTime(&StreamTime, StreamStart, StreamStop); printf("스트림 실행시간: %f msec\n",StreamTime); cudaEventDestroy(StreamStart); cudaEventDestroy(StreamStop); for(int i = 0; i < nStreams; i++) cudaStreamDestroy(streams[i]); cudaFree(dev_In); cudaFree(dev_Out); cudaFreeHost(host_In); cudaFreeHost(host_Out); return 0; }
| 커널함수 (0) | 2017.01.16 |
|---|---|
| 고정 메모리와 제로 메모리 그리고 포터블 메모리. (0) | 2017.01.03 |
| 메모리 타입. (0) | 2017.01.03 |
| CUDA 컴파일 옵션. (0) | 2017.01.03 |
| 쓰레드 ID 구하기. (0) | 2016.12.29 |
- 가상메모리를 사용하지 않고, 메모리에 직접 접근하여 처리하는 접근 방식.
- 가상 메모리와 물리적 메모리간의 치환 제거.
- CUDA 스트림을 사용하기 위해서는 고정 메모리는 필수다.
- 관련 함수
1. cudaMallocHost
2. cudaFreeHost
- 호스트와 디바이스간에 메모리 복사를 하지 않고, 고정된 메모리[Pinned Memory]영역에 바로 엑세스하여 데이터를 읽고 쓸수 있는 메모리.
- PCI를 사용해서 전송 속다가 빨라 지는 것은 아니지만.
- 데이터를 계산하고, 결과값을 메모리에 쓰면 비동기 양방향 PCI 전송이 진행되기 때문에, 그 만큼 성능향상을 볼 수 있다.
- 전제조건
- 맵드 메모리를 사용할 때, 글로벌 메모리의 결합 전송과 동일한 조건을 커널에서 충족시켜야 한다.
글로벌 메모리 결합 전송조건.
- 글로벌 메모리를 읽어 올 때 최대 밴드 폭을 사용할 수 있는 조건 - 사실 최신 사양에서는 무시해도 되지 않나 싶다.[개인생각]
- 커널에서 작은 크기의 데이터를 많은 횟수로 맵드 메모리를 엑세스 하게 되면, 통상적인 데이터 전송보다 떨어지는 효과를 얻을 수 있다.
1 cudaHostAlloc
2 cudaHostGetDevicePointer
3 예제:
- 제로 메모리는 하나의 디바이스에서만 유효하기 때문에, 두개의 디바이스상에서 문제가 된다. 즉 두개의 호스트 스레드를 생성하여 처리하게 되는데, 이 때 하나의 스레드에서 생성한 고정된 메모리는 다른 쓰레드에서는 사용할 수 없게 되어, 자원 낭비를 하게 된다.
이런 자원 낭비를 피하고자 사용하는 것이 포터블 고정 메모리라고 한다.
- 적용.
cudaHostAlloc() 세번째 파라미터: cudaHostAllocMapped | cudaHostAllocPortable 옵션 지정.
| 커널함수 (0) | 2017.01.16 |
|---|---|
| 스트림. (0) | 2017.01.04 |
| 메모리 타입. (0) | 2017.01.03 |
| CUDA 컴파일 옵션. (0) | 2017.01.03 |
| 쓰레드 ID 구하기. (0) | 2016.12.29 |
- 쓰래드 내부에서 몇 개를 사용하는지는 알 수 없다. 다만 툴을 이용해서 확인은 가능.
- 단항연산을 할수록, 사용하는 레지스터 갯수는 줄어든다.

| 스트림. (0) | 2017.01.04 |
|---|---|
| 고정 메모리와 제로 메모리 그리고 포터블 메모리. (0) | 2017.01.03 |
| CUDA 컴파일 옵션. (0) | 2017.01.03 |
| 쓰레드 ID 구하기. (0) | 2016.12.29 |
| Nsight - Performance Analysis (0) | 2016.12.29 |
-maxrregcount : 쓰레드당 사용할 수 있는 레지스터 개수를 지정할 수 있다.
초과 되었을 경우, 로컬 메모리[DRAM] 를 사용하게 된다.
| 고정 메모리와 제로 메모리 그리고 포터블 메모리. (0) | 2017.01.03 |
|---|---|
| 메모리 타입. (0) | 2017.01.03 |
| 쓰레드 ID 구하기. (0) | 2016.12.29 |
| Nsight - Performance Analysis (0) | 2016.12.29 |
| CUDA Debugging - Nsight (0) | 2016.12.29 |
__device__ int getGlobalIdx_1D_1D()
{
return blockIdx.x *blockDim.x + threadIdx.x;
}
__device__ int getGlobalIdx_1D_2D()
{
return blockIdx.x * blockDim.x * blockDim.y + threadIdx.y * blockDim.x + threadIdx.x;
}
__device__ int getGlobalIdx_1D_3D()
{
return blockIdx.x * blockDim.x * blockDim.y * blockDim.z + threadIdx.z * blockDim.y * blockDim.x + threadIdx.y * blockDim.x + threadIdx.x;
}
__device__ int getGlobalIdx_2D_1D()
{
int blockId = blockIdx.y * gridDim.x + blockIdx.x;
int threadId = blockId * blockDim.x + threadIdx.x;
return threadId;
}
__device__ int getGlobalIdx_2D_2D()
{
int blockId = blockIdx.x + blockIdx.y * gridDim.x;
int threadId = blockId * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x;
return threadId;
}
__device__ int getGlobalIdx_2D_3D()
{
int blockId = blockIdx.x
+ blockIdx.y * gridDim.x;
int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z)
+ (threadIdx.z * (blockDim.x * blockDim.y))
+ (threadIdx.y * blockDim.x)
+ threadIdx.x;
return threadId;
}
__device__ int getGlobalIdx_3D_1D()
{
int blockId = blockIdx.x
+ blockIdx.y * gridDim.x
+ gridDim.x * gridDim.y * blockIdx.z;
int threadId = blockId * blockDim.x + threadIdx.x;
return threadId;
}
__device__ int getGlobalIdx_3D_2D()
{
int blockId = blockIdx.x
+ blockIdx.y * gridDim.x
+ gridDim.x * gridDim.y * blockIdx.z;
int threadId = blockId * (blockDim.x * blockDim.y)
+ (threadIdx.y * blockDim.x)
+ threadIdx.x;
return threadId;
}
__device__ int getGlobalIdx_3D_3D()
{
int blockId = blockIdx.x
+ blockIdx.y * gridDim.x
+ gridDim.x * gridDim.y * blockIdx.z;
int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z)
+ (threadIdx.z * (blockDim.x * blockDim.y))
+ (threadIdx.y * blockDim.x)
+ threadIdx.x;
return threadId;
}
| 메모리 타입. (0) | 2017.01.03 |
|---|---|
| CUDA 컴파일 옵션. (0) | 2017.01.03 |
| Nsight - Performance Analysis (0) | 2016.12.29 |
| CUDA Debugging - Nsight (0) | 2016.12.29 |
| CUDA Visual Profiler (0) | 2016.12.28 |


