분류 전체보기
- dll 버전으로 사용할 때, stdafx.h 선언해줘야 할 상수값. 2018.08.13
- 대화상자 - 키보드 처리[엔터,ESC] 로 인한 종료 방지 코드 2018.05.15
- 각 언어별 AI라이브러리 2018.04.22
- C++17, structure binding, if(init; condition) switch(init;condition) 2018.04.18
- 툴 업데이트 후, 발생되는 에러에 대한 처리. - 캐쉬파일 삭제. 2018.04.17
- C++ override final keyword 2018.04.11
- C++ 11 ENUM 2018.04.11
- auto keyword 2018.04.05
- Aggregate and POD 2018.04.04
- OUTLOOK PLUG IN 2018.04.04
dll 버전으로 사용할 때, stdafx.h 선언해줘야 할 상수값.
2018. 8. 13. 11:11
대화상자 - 키보드 처리[엔터,ESC] 로 인한 종료 방지 코드
2018. 5. 15. 10:55
BOOL CSample::PreTranslateMessage(MSG* pMsg)
{
switch (pMsg->message)
{
case WM_KEYDOWN:
case WM_KEYUP:
switch (pMsg->wParam)
{
case VK_RETURN:
case VK_ESCAPE:
case VK_SPACE:
case VK_CANCEL:
return TRUE;
}
break;
case WM_SYSKEYDOWN:
switch (pMsg->wParam)
{
case VK_F4:
return TRUE;
}
}
return CBCGPDialog::PreTranslateMessage(pMsg);
}
각 언어별 AI라이브러리
2018. 4. 22. 09:54
AI Korea Open 그룹에서도 라이브러리에 관한 투표가 있었고, 많은 분들이 관심있어할 만한 부분이라 생각해서 한 번 정리해 봤습니다!
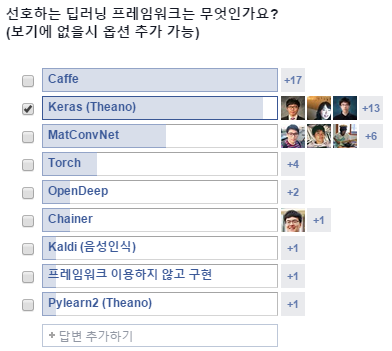 (AI Korea Open 그룹의 투표 결과)
(AI Korea Open 그룹의 투표 결과)
Python
요즘 뜨는 언어답게, 대부분의 라이브러리들이 빠른 속도로 업데이트되며 새로운 기능이 계속 추가되고 있다.
- Theano - 수식 및 행렬 연산을 쉽게 만들어주는 파이썬 라이브러리. 딥러닝 알고리즘을 파이썬으로 쉽게 구현할 수 있도록 해주는데, Theano 기반 위에 얹어서 더 사용하기 쉽게 구현된 여러 라이브러리가 있다.
- Chainer - 거의 모든 딥러닝 알고리즘을 직관적인 Python 코드로 구현할 수 있고, 자유도가 매우 높음. 대다수의 다른 라이브러리들과는 다르게 "Define-by-Run" 형태로 구현되어 있어서, forward 함수만 정의해주면 네트워크 구조가 자동으로 정해진다는 점이 특이하다.
- nolearn - scikit-learn과 연동되며 기계학습에 유용한 여러 함수를 담고 있음.
- Gensim - 큰 스케일의 텍스트 데이터를 효율적으로 다루는 것을 목표로 한 Python 기반 딥러닝 툴킷
- deepnet - cudamat과 cuda-convnet 기반의 딥러닝 라이브러리
- CXXNET - MShadow 라이브러리 기반으로 멀티 GPU까지 지원하며, Python 및 Matlab 인터페이스 제공
- DeepPy - NumPy 기반의 라이브러리
- Neon - Nervana에서 사용하는 딥러닝 프레임워크
Matlab
- MatConvNet - 컴퓨터비젼 분야에서 유명한 매트랩 라이브러리인 vlfeat 개발자인 Oxford의 코딩왕 Andrea Vedaldi 교수와 학생들이 관리하는 라이브러리.
- ConvNet - CNN 라이브러리
- DeepLearnToolbox - DBN, Stacked Autoencoder, CNN 등의 딥러닝을 위한 matlab/octave 툴박스
C++
- Caffe - Berkeley 대학에서 관리하고 있고, 현재 가장 많은 사람들이(추정) 사용하고 있는 라이브러리. C++로 직접 사용할 수도 있지만 Python과 Matlab 인터페이스도 잘 구현되어 있다.
- DIGITS - NVIDIA에서 브라우저 기반 인터페이스로 쉽게 신경망 구조를 구현, 학습, 시각화할 수 있도록 개발한 시스템.
- cuda-convnet - 딥러닝 슈퍼스타인 Alex Krizhevsky와 Geoff Hinton이 ImageNet 2012 챌린지를 우승할 때 사용한 라이브러리
- eblearn - 딥러닝 계의 또하나의 큰 축인 NYU의 Yann LeCun 그룹에서 ImageNet 2013 챌린지를 우승할 때 사용한 라이브러리
- SINGA - 기존의 시스템에서 동작하는 분산처리 학습 알고리즘을 일반적으로 구현하기 위해 만들어진 플랫폼으로 Apache Software Foundation의 후원을 받고 있다.
Java
- ND4J - N-Dimensional Arrays for Java. JVM을 위한 과학 연산 라이브러리로 상용 제품에 사용될 수 있게 연산들이 최소한의 메모리 사용으로 빠르게 작동하게 끔 만들어졌다.
- Deeplearning4j - Java와 Scala로 작성된 첫 상용 수준의 오픈소스 분산처리 딥러닝 라이브러리. 개발툴보다는 business 환경에 적합하도록 작성되었다.
- Encog -머신러닝 프레임워크로 SVM, ANN, Genetic Programming, Genetic Algorithm, Bayesian Network, Hidden Markov Model 등을 지원한다.
JavaScript
자바스크립트로의 딥러닝 구현은 Stanford의 Andrej Karpathy가 혼자서 개발했음에도 불구하고 높은 완성도를 보이며 널리 사용되고 있는 아래 두 라이브러리가 가장 유명하다.
- ConvnetJS - 딥러닝 모델의 학습을 완전히 브라우저에서 할 수 있게 하는 자바스크립트 라이브러리. 별도의 소프트웨어, 컴파일러, 설치, GPU 없이 쉽게 사용할 수 있다.
- RecurrentJS - RNN/LSTM을 구현한 Javascript 라이브러리
Lua
- Torch - 페이스북과 구글 딥마인드에서 사용하는 라이브러리. 양대 대기업에서 사용하고 있는 만큼 필요한 거의 모든 기능이 잘 구현되어 있고, 스크립트 언어인 Lua를 사용하기 때문에 쉽게 사용 가능하다.
Julia
MIT에서 새로 개발한 언어로, 최근에 주목받기 시작하여 효율적인 딥 러닝 라이브러리도 여러 가지 구현되었다.
- Mocha.jl - C++ 프레임워크인 Caffe에 영감을 받아 만들어진 Julia 기반의 딥러닝 프레임워크. Mocha의 General stochastic solver와 공통 레이어를 사용해 deep / shallow(convolutional) neural network를 학습하고 (stacked) auto-encoder를 통해 unsupervised pre-training을 할 수 있다. 모듈화된 구조, 하이 레벨 인터페이스, 이식성, 빠른 속도, 호환성등을 특징으로 한다.
- Strada.jl - Caffe 프레임워크를 기반으로 해 만들어진 오픈소스 딥러닝 라이브러리. CNN과 RNN을 CPU/GPU로 학습할 수 있다.
- KUnet.jl - 최대한 적은 양의 코드로 작성하고자 하는 시도에서 만들어진 딥러닝 패키지. 현재 1000 라인 미만의 코드로 여러 네트워크, activation, optimization을 구현하고 있고, CPU/GPU를 사용해 Caffe와 비슷한 성능으로 학습할 수 있다고 한다.
Lisp
- Lush - Lisp Universal Shell. 대규모 수치, 그래픽 어플리케이션을 위한 객체 지향 프로그래밍 언어. 딥러닝 라이브러리가 머신러닝 라이브러리에 포함되어 제공된다.
Haskell
- DNNGraph - Haskell로 작성된 deep neural network 모델 생성 DSL(domain-specific language)
.NET
- Accord.NET - C#으로만 작성된 .NET 머신러닝 프레임워크로 음성, 이미지 처리 라이브러리가 포함되어 있다. 상용 수준의 컴퓨터 비전, 컴퓨터 음성인식, 신호처리, 통계 어플리케이션을 만들 수 있다.
R
- darch - 레이어가 많은 neural network(deep architecture)를 만들 수 있다. contrastive divergence로 pre-training 하거나 backpropagation, conjugate gradient와 같은 알고리즘을 사용한 fine tuning으로 학습할 수 있다.
- deepnet - BP, RBM, DBN, Deep autoencoder 등의 딥러닝 아키텍쳐, neural network 알고리즘을 구현한 패키지.
출처:http://aikorea.org/blog/dl-libraries/
C++17, structure binding, if(init; condition) switch(init;condition)
2018. 4. 18. 13:06
툴 업데이트 후, 발생되는 에러에 대한 처리. - 캐쉬파일 삭제.
2018. 4. 17. 23:41
C++ override final keyword
2018. 4. 11. 00:39
C++ 11 ENUM
2018. 4. 11. 00:31
auto keyword
2018. 4. 5. 00:14
auto
- 선언으로부터 데이터를 자동으로 유추해서, 컴파일러가 알아서 타입을 지정해주는 키워드.
이점
1. 선언가 동시에 초기화를 해줘야 하기때문에, 초기화를 하지 않아 발생되는 버그를 예방할 수 있다.
2. 함수의 리턴 타입과 받는 타입이 달라 발생될 수 있는 버그를 예방 할 수 있다.
ex) vector 등의 size()는 size_t 타입이지만, 보통, int 형으로 반환받을 경우가 많은데, 자료형 바이트 크기가 달라 문제가 발생될 수 있다.
vector<int> vecData{1,2,3,4,5};
auto nSize = vecData.size();
auto nSize2 = int{vecData.size()}; //에러 발생. not allow narrowing conversion.
3. 처리해야 할 자료형에 대해서 신경을 안써도 된다.
vector<int>::iterator iter = vecData.begin(); 보단.
auto iter = vecData.begin() 으로 처리할 수 있어. 반환 타입을 신경쓰지 않아도 된다.
auto iterEnd = vecData.end();
for(auto iter = vecData.begin(); iter != iterEnd; iter++)
{
}
주의사항
이동할 수 잆는 자료형은 AUTO를 사용할 수 없다.
atomic<int> m_nData = 20;
auto atomicData = m_nData;
class CTest
{
public:
CTest() = delete;
};
auto classObject = CTest(); 이경우도 에러.
'C++ > C++ 11 14 17' 카테고리의 다른 글
| C++17, structure binding, if(init; condition) switch(init;condition) (0) | 2018.04.18 |
|---|---|
| C++ 11 ENUM (0) | 2018.04.11 |
| Aggregate and POD (0) | 2018.04.04 |
| 함수포인터, std::function (0) | 2017.04.19 |
| R 레퍼런스 타입. (0) | 2017.01.30 |
Aggregate and POD
2018. 4. 4. 23:38
This article is rather long. If you want to know about both aggregates and PODs (Plain Old Data) take time and read it. If you are interested just in aggregates, read only the first part. If you are interested only in PODs then you must first read the definition, implications, and examples of aggregates and then you may jump to PODs but I would still recommend reading the first part in its entirety. The notion of aggregates is essential for defining PODs. If you find any errors (even minor, including grammar, stylistics, formatting, syntax, etc.) please leave a comment, I'll edit.
What are aggregates and why they are special
Formal definition from the C++ standard (C++03 8.5.1 §1):
An aggregate is an array or a class (clause 9) with no user-declared constructors (12.1), no private or protected non-static data members (clause 11), no base classes (clause 10), and no virtual functions (10.3).
So, OK, let's parse this definition. First of all, any array is an aggregate. A class can also be an aggregate if… wait! nothing is said about structs or unions, can't they be aggregates? Yes, they can. In C++, the term class refers to all classes, structs, and unions. So, a class (or struct, or union) is an aggregate if and only if it satisfies the criteria from the above definitions. What do these criteria imply?
This does not mean an aggregate class cannot have constructors, in fact it can have a default constructor and/or a copy constructor as long as they are implicitly declared by the compiler, and not explicitly by the user
No private or protected non-static data members. You can have as many private and protected member functions (but not constructors) as well as as many private or protected static data members and member functions as you like and not violate the rules for aggregate classes
An aggregate class can have a user-declared/user-defined copy-assignment operator and/or destructor
An array is an aggregate even if it is an array of non-aggregate class type.
Now let's look at some examples:
class NotAggregate1
{
virtual void f() {} //remember? no virtual functions
};
class NotAggregate2
{
int x; //x is private by default and non-static
};
class NotAggregate3
{
public:
NotAggregate3(int) {} //oops, user-defined constructor
};
class Aggregate1
{
public:
NotAggregate1 member1; //ok, public member
Aggregate1& operator=(Aggregate1 const & rhs) {/* */} //ok, copy-assignment
private:
void f() {} // ok, just a private function
};You get the idea. Now let's see how aggregates are special. They, unlike non-aggregate classes, can be initialized with curly braces {}. This initialization syntax is commonly known for arrays, and we just learnt that these are aggregates. So, let's start with them.
Type array_name[n] = {a1, a2, …, am};
if(m == n)
the ith element of the array is initialized with ai
else if(m < n)
the first m elements of the array are initialized with a1, a2, …, am and the other n - m elements are, if possible, value-initialized (see below for the explanation of the term)
else if(m > n)
the compiler will issue an error
else (this is the case when n isn't specified at all like int a[] = {1, 2, 3};)
the size of the array (n) is assumed to be equal to m, so int a[] = {1, 2, 3}; is equivalent to int a[3] = {1, 2, 3};
When an object of scalar type (bool, int, char, double, pointers, etc.) is value-initialized it means it is initialized with 0 for that type (false for bool, 0.0 for double, etc.). When an object of class type with a user-declared default constructor is value-initialized its default constructor is called. If the default constructor is implicitly defined then all nonstatic members are recursively value-initialized. This definition is imprecise and a bit incorrect but it should give you the basic idea. A reference cannot be value-initialized. Value-initialization for a non-aggregate class can fail if, for example, the class has no appropriate default constructor.
Examples of array initialization:
class A
{
public:
A(int) {} //no default constructor
};
class B
{
public:
B() {} //default constructor available
};
int main()
{
A a1[3] = {A(2), A(1), A(14)}; //OK n == m
A a2[3] = {A(2)}; //ERROR A has no default constructor. Unable to value-initialize a2[1] and a2[2]
B b1[3] = {B()}; //OK b1[1] and b1[2] are value initialized, in this case with the default-ctor
int Array1[1000] = {0}; //All elements are initialized with 0;
int Array2[1000] = {1}; //Attention: only the first element is 1, the rest are 0;
bool Array3[1000] = {}; //the braces can be empty too. All elements initialized with false
int Array4[1000]; //no initializer. This is different from an empty {} initializer in that
//the elements in this case are not value-initialized, but have indeterminate values
//(unless, of course, Array4 is a global array)
int array[2] = {1, 2, 3, 4}; //ERROR, too many initializers
}Now let's see how aggregate classes can be initialized with braces. Pretty much the same way. Instead of the array elements we will initialize the non-static data members in the order of their appearance in the class definition (they are all public by definition). If there are fewer initializers than members, the rest are value-initialized. If it is impossible to value-initialize one of the members which were not explicitly initialized, we get a compile-time error. If there are more initializers than necessary, we get a compile-time error as well.
struct X
{
int i1;
int i2;
};
struct Y
{
char c;
X x;
int i[2];
float f;
protected:
static double d;
private:
void g(){}
};
Y y = {'a', {10, 20}, {20, 30}};In the above example y.c is initialized with 'a', y.x.i1 with 10, y.x.i2 with 20, y.i[0] with 20, y.i[1] with 30 and y.f is value-initialized, that is, initialized with 0.0. The protected static member d is not initialized at all, because it is static.
Aggregate unions are different in that you may initialize only their first member with braces. I think that if you are advanced enough in C++ to even consider using unions (their use may be very dangerous and must be thought of carefully), you could look up the rules for unions in the standard yourself :).
Now that we know what's special about aggregates, let's try to understand the restrictions on classes; that is, why they are there. We should understand that memberwise initialization with braces implies that the class is nothing more than the sum of its members. If a user-defined constructor is present, it means that the user needs to do some extra work to initialize the members therefore brace initialization would be incorrect. If virtual functions are present, it means that the objects of this class have (on most implementations) a pointer to the so-called vtable of the class, which is set in the constructor, so brace-initialization would be insufficient. You could figure out the rest of the restrictions in a similar manner as an exercise :).
So enough about the aggregates. Now we can define a stricter set of types, to wit, PODs
What are PODs and why they are special
Formal definition from the C++ standard (C++03 9 §4):
A POD-struct is an aggregate class that has no non-static data members of type non-POD-struct, non-POD-union (or array of such types) or reference, and has no user-defined copy assignment operator and no user-defined destructor. Similarly, a POD-union is an aggregate union that has no non-static data members of type non-POD-struct, non-POD-union (or array of such types) or reference, and has no user-defined copy assignment operator and no user-defined destructor. A POD class is a class that is either a POD-struct or a POD-union.
Wow, this one's tougher to parse, isn't it? :) Let's leave unions out (on the same grounds as above) and rephrase in a bit clearer way:
An aggregate class is called a POD if it has no user-defined copy-assignment operator and destructor and none of its nonstatic members is a non-POD class, array of non-POD, or a reference.
What does this definition imply? (Did I mention POD stands for Plain Old Data?)
- All POD classes are aggregates, or, to put it the other way around, if a class is not an aggregate then it is sure not a POD
- Classes, just like structs, can be PODs even though the standard term is POD-struct for both cases
- Just like in the case of aggregates, it doesn't matter what static members the class has
Examples:
struct POD
{
int x;
char y;
void f() {} //no harm if there's a function
static std::vector<char> v; //static members do not matter
};
struct AggregateButNotPOD1
{
int x;
~AggregateButNotPOD1() {} //user-defined destructor
};
struct AggregateButNotPOD2
{
AggregateButNotPOD1 arrOfNonPod[3]; //array of non-POD class
};POD-classes, POD-unions, scalar types, and arrays of such types are collectively called POD-types.
PODs are special in many ways. I'll provide just some examples.
POD-classes are the closest to C structs. Unlike them, PODs can have member functions and arbitrary static members, but neither of these two change the memory layout of the object. So if you want to write a more or less portable dynamic library that can be used from C and even .NET, you should try to make all your exported functions take and return only parameters of POD-types.
The lifetime of objects of non-POD class type begins when the constructor has finished and ends when the destructor has finished. For POD classes, the lifetime begins when storage for the object is occupied and finishes when that storage is released or reused.
For objects of POD types it is guaranteed by the standard that when you
memcpythe contents of your object into an array of char or unsigned char, and thenmemcpythe contents back into your object, the object will hold its original value. Do note that there is no such guarantee for objects of non-POD types. Also, you can safely copy POD objects withmemcpy. The following example assumes T is a POD-type:#define N sizeof(T) char buf[N]; T obj; // obj initialized to its original value memcpy(buf, &obj, N); // between these two calls to memcpy, // obj might be modified memcpy(&obj, buf, N); // at this point, each subobject of obj of scalar type // holds its original valuegoto statement. As you may know, it is illegal (the compiler should issue an error) to make a jump via goto from a point where some variable was not yet in scope to a point where it is already in scope. This restriction applies only if the variable is of non-POD type. In the following example
f()is ill-formed whereasg()is well-formed. Note that Microsoft's compiler is too liberal with this rule—it just issues a warning in both cases.int f() { struct NonPOD {NonPOD() {}}; goto label; NonPOD x; label: return 0; } int g() { struct POD {int i; char c;}; goto label; POD x; label: return 0; }It is guaranteed that there will be no padding in the beginning of a POD object. In other words, if a POD-class A's first member is of type T, you can safely
reinterpret_castfromA*toT*and get the pointer to the first member and vice versa.
The list goes on and on…
Conclusion
It is important to understand what exactly a POD is because many language features, as you see, behave differently for them.
'C++ > C++ 11 14 17' 카테고리의 다른 글
| C++ 11 ENUM (0) | 2018.04.11 |
|---|---|
| auto keyword (0) | 2018.04.05 |
| 함수포인터, std::function (0) | 2017.04.19 |
| R 레퍼런스 타입. (0) | 2017.01.30 |
| Modern C++ [MS] (0) | 2016.12.28 |
OUTLOOK PLUG IN
2018. 4. 4. 09:39
https://www.codeproject.com/Articles/522094/Outlook-add-in-using-VCplusplus-ATL-COM
'팁 > URL' 카테고리의 다른 글
| 펌] 각 언어별 딥러닝~ 라이브러리. (0) | 2017.01.17 |
|---|---|
| CUDA (0) | 2016.12.12 |
| GIT 튜토리얼. (0) | 2016.12.08 |
| NVIDIA, CUDA (0) | 2016.11.23 |